











人工智能(AI)图像编辑及生成模型获广泛应用于图像创作,然而其对抽象概念如感觉和氛围等理解精准度一直存在局限,且多依赖纯文字指令,较难准确表达复杂图像意思,亦无法捕捉风格、材质或光影等效果。 由香港科技大学(科大)冯诺依曼研究院院长兼计算机科学及工程学系讲座教授贾佳亚教授带领的团队成功开发名为「DreamOmni2」的AI图像生成和编辑器,不仅拥有卓越的多模态指令编辑和实体对象生成能力,更在抽象概念的理解和生成方面有重大突破,让AI不仅能「看图」,更能「理解图意」,多方面表现优于同类型开源和闭源模型, 为AI创作开启无限可能。
直击缺陷:解锁抽象概念的创作潜能
近年,图像编辑及生成模型的发展进入爆发阶段,新品频出,但暂时仍未有任何模型能彻底克服实际作上遇到的两大缺陷。 其一是文本指令的局限性,纯文字指令难以准确描述人物特征、抽象纹理等细节。 其二是抽象概念的缺失,现有模型仅能处理有形实体,如人物、对象,无法有效应对发型、妆容、纹理、光影效果或风格等抽象概念,极大程度上限制了创作空间。 DreamOmni2则可解决有关难题,成功执行两大全新任务,包括根据用家输入的抽象或实体概念,执行多模态指令编辑和生成,真正成为「全能创作工具」。
全面性能测试:超越现有开源与闭源模型
在多模态指令生成任务中,DreamOmni2能基于图片中的实体进行图像生成,例如提取图一的画作挂在卧室墙上,将图二盘子的材质套用在图三的水杯,并将水杯放置在桌子上,以生成符合用家要求的新图像(图示一)。
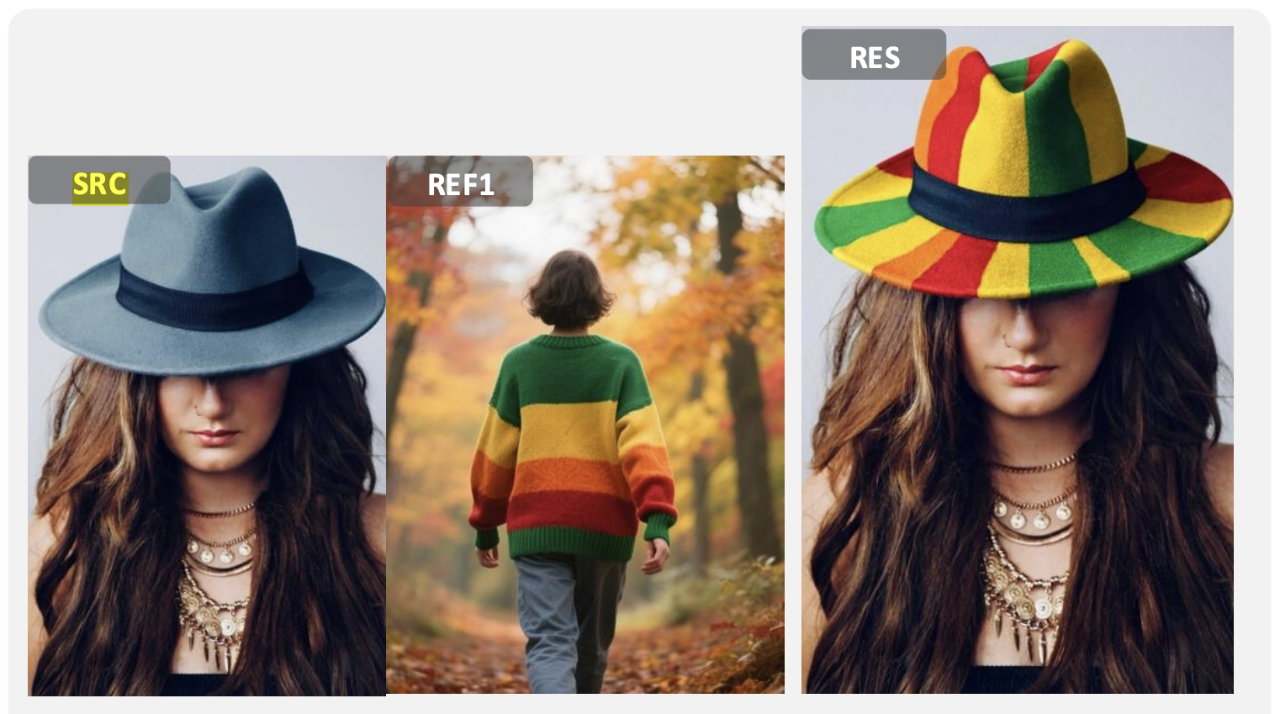
在多模态指令编辑任务中,DreamOmni2的表现亦非常优秀,例如将图中帽子的颜色变成与另一张图毛衣相同的配色(图示二)。
在同类模型对比中,当团队给予多模态指令,让图中人物手执另一张图的物品,以生成新图像。 结果显示,无论是参考对象的一致性,还是指令的遵循度,DreamOmni2的表现最佳(图示三)。
整体而言,与SOTA开源模型相比,DreamOmni2在实体及抽象概念的多模态指令编辑表现更佳,在抽象概念指令编辑方面亦优于商业模型Nano Banana,更解决了其他现有模型难以控制生成图像泛黄或细节改变的问题。
新数据构建 确保图像质量
DreamOmni2以创新的三阶段数据构建模式,提高模型的多模态指令生成和编辑能力。
第一阶段:特征混合
利用基础模型由文字到图像生成的能力,构建包含具体对象与抽象属性的高质量训练数据。第二阶段:训练多模态指令编辑能力
训练模型提取靶心图表中的对象或属性,并根据指令生成参考图像,以及使用编辑模型修改靶心图表,通过完整训练提升编辑能力。第三阶段:训练多模态指令生成能力
训练模型从源图像中提取对象,以创建全新参考图像的能力。
框架设计突破 克服多图输入难题
FLUX Kontext是全球首款基于指令的图像编辑器,但不支持多图输入,而DreamOmni2是基于FLUX-Kontext训练的模型,除了延续原有指令编辑和文本生成能力外,更拥有多参考图生成和编辑能力。 DreamOmni2采用的先进技术,包括:
索引编码技术
在位置通道中添加索引编码,以有效区分不同参考图像的身份,提升输入的处理精准度。位置编码偏移机制
能根据输入的参考图像大小,动态调整位置编码,显著减少图像在复制和贴上时与参考图混淆的问题。视觉语言联合训练
为解决用家指令不规则、逻辑复杂的挑战,团队以视觉语言模型(VLM)与生成模型进行联合训练,使VLM能更好地理解复杂指令并转化为结构化格式,大幅提升模型在真实场景的应用表现。
开放公众使用 应用前景无限
DreamOmni2已于著名国际开源社区Github开放予公众使用,更获得数字艺术创作者认可支持,赞赏模型在理解氛围感和抽象风格方面表现卓越,大幅降低了创作复杂图像的门槛。
贾佳亚教授表示:「DreamOmni2标志着多模态生成技术迈入全新阶段,其不仅在性能上超越现有模型,更在技术架构上为AI图像生成和编辑模型的未来发展奠定坚实基础,为生成式人工智能产业注入新动能,同时为数字艺术设计、个性化媒体制作等领域带来革命性改变,助力香港产学研和科研生态的蓬勃。」
注册收取我们的最新消息
最新消息

太阳能电池的效能与寿命往往取决于材料之间的微小界面。香港科技大学(科大)研究人员近日参与两项研究,发现透过精准设计的分子界面层,可显著提升新一代钙钛矿迭层太阳能电池的效能及耐用性。
两项研究分别刊登于学术期刊《Joule》(影响因子为37.1)及《自然—通讯》,虽然针对不同迭层架构,却带出同一个核心讯息:分子界面并非单纯连接不同材料的被动层,而是可主动引导钙钛矿薄膜结晶、减少能量损失、促进电荷传输,并保护器件免受退化影响的重要设计平台。
这两项研究由科大电子及计算机工程学系助理教授林彦宏教授及科大显示与光电子全国重点实验室高级经理杨思恩博士共同带领,充分结合科大在钙钛矿界面设计、光学表征及迭层器件物理方面的科研优势。其中,科大电子及计算机工程学系研究助理教授李凤珠博士领导《Joule》论文的研究工作;科大电子及计算机工程学系博士研究生张青清女士则为《自然—通讯》论文的主要研究团队成员之一。

由香港大湾区围棋促进会及香港科技大学(科大)联合主办的第四届「四洲杯」香港国际大学生围棋公开赛,于7月14日至18日在科大校园隆重举行。赛事开幕典礼于今日(7月15日)在科大逸夫演艺中心盛大举行,并非常荣幸邀请到香港特别行政区政府教育局局长蔡若莲博士等重量级嘉宾莅临主礼。出席开幕仪式的嘉宾亦包括:香港大湾区围棋促进会会长徐莹女士、科大副校长(大学拓展)吴宏伟教授、四洲集团创办人兼主席戴德丰博士、深圳市文化广电旅游体育局副局长何建辉先生、中央政府驻港联络办宣传文体部副部长林枬先生、外交部驻港特派员公署发言人兼新闻及公共关系部主任黄景睿先生、 新华社亚太总分社社长孙承斌先生、中央广播电视总台香港记者站站长王喜凯先生、中央广播电视总台亚太总站副站长李风先生、先施集团主席、全国政协委员林晓晖先生、香港新闻工作者联会会长张国良先生及科大跨学科学院院长屈华民教授等。
莱韵诗博士(右)与印尼高等教育、科学及科技部科学与科技总司转型学习策略与制度处处长Ardi FINDYARTINI 教授(左)于仪式上合照。")
香港科技大学(科大)与印尼高等教育、科学及科技部签署合作备忘录,加强落实印尼政府资助奖学金框架,以培育卓越人才。 是次合作进一步深化双方伙伴关系,透过印尼最新推出的《嘉鲁达奖学金》(the Garuda Scholarship),支持更多优秀印尼学生赴科大修读本科课程。 此合作备忘录基于双方于2024年5月签订的合作协议,旨在巩固既有的奖学金机制,同时为双方未来在学生实习、学术交流及科研合作等领域探讨更多协同发展机会铺路,携手推动高等教育与创新科技发展。
协议早前由印尼高等教育、科学与科技部署任秘书长Badri Munir SUKOCO 教授及科大协理副校长(学术策略及数据分析)莱韵诗博士正式签署。 随着协议落实,科大亦将于今年九月展开的新学年迎来第五批由印尼政府资助的优秀本科生。