











人工智能(AI)圖像編輯及生成模型獲廣泛應用於圖像創作,然而其對抽象概念如感覺和氛圍等理解精準度一直存在局限,且多依賴純文字指令,較難準確表達複雜圖像意思,亦無法捕捉風格、材質或光影等效果。由香港科技大學(科大)馮諾依曼研究院院長兼計算機科學及工程學系講座教授賈佳亞教授帶領的團隊成功開發名為「DreamOmni2」的AI圖像生成和編輯器,不僅擁有卓越的多模態指令編輯和實體物件生成能力,更在抽象概念的理解和生成方面有重大突破,讓AI不僅能「看圖」,更能「理解圖意」,多方面表現優於同類型開源和閉源模型,為AI創作開啟無限可能。
直擊缺陷:解鎖抽象概念的創作潛能
近年,圖像編輯及生成模型的發展進入爆發階段,新品頻出,但暫時仍未有任何模型能徹底克服實際操作上遇到的兩大缺陷。其一是文本指令的局限性,純文字指令難以準確描述人物特徵、抽象紋理等細節。其二是抽象概念的缺失,現有模型僅能處理有形實體,如人物、物件,無法有效應對髮型、妝容、紋理、光影效果或風格等抽象概念,極大程度上限制了創作空間。DreamOmni2則可解決有關難題,成功執行兩大全新任務,包括根據用家輸入的抽象或實體概念,執行多模態指令編輯和生成,真正成為「全能創作工具」。
全面性能測試:超越現有開源與閉源模型
在多模態指令生成任務中,DreamOmni2能基於圖片中的實體進行圖像生成,例如提取圖一的畫作掛在臥室牆上,將圖二盤子的材質套用在圖三的水杯,並將水杯放置在桌子上,以生成符合用家要求的新圖像(圖示一)。
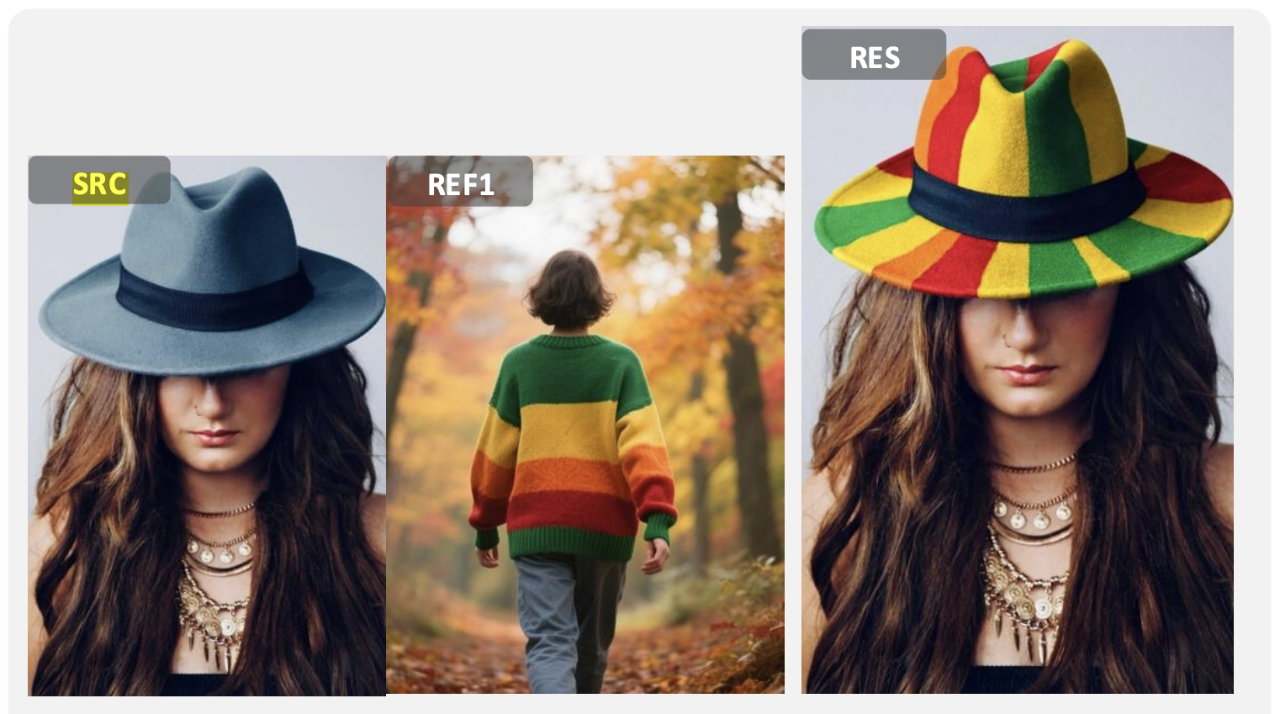
在多模態指令編輯任務中,DreamOmni2的表現亦非常優秀,例如將圖中帽子的顏色變成與另一張圖毛衣相同的配色(圖示二)。
在同類模型對比中,當團隊給予多模態指令,讓圖中人物手執另一張圖的物品,以生成新圖像。結果顯示,無論是參考物件的一致性,還是指令的遵循度,DreamOmni2的表現最佳(圖示三)。
整體而言,與SOTA開源模型相比,DreamOmni2在實體及抽象概念的多模態指令編輯表現更佳,在抽象概念指令編輯方面亦優於商業模型Nano Banana,更解決了其他現有模型難以控制生成圖像泛黃或細節改變的問題。
新數據建構 確保圖像質量
DreamOmni2以創新的三階段資料建構模式,提高模型的多模態指令生成和編輯能力。
第一階段:特徵混合
利用基礎模型由文字到圖像生成的能力,構建包含具體物件與抽象屬性的高質量訓練數據。第二階段:訓練多模態指令編輯能力
訓練模型提取靶心圖表中的物件或屬性,並根據指令生成參考圖像,以及使用編輯模型修改靶心圖表,透過完整訓練提升編輯能力。第三階段:訓練多模態指令生成能力
訓練模型從源圖像中提取物件,以創建全新參考圖像的能力。
框架設計突破 克服多圖輸入難題
FLUX Kontext是全球首款基於指令的圖像編輯器,但不支援多圖輸入,而DreamOmni2是基於 FLUX-Kontext訓練的模型,除了延續原有指令編輯和文本生成能力外,更擁有多參考圖生成和編輯能力。DreamOmni2採用的先進技術,包括:
索引編碼技術
在位置通道中添加索引編碼,以有效區分不同參考圖像的身份,提升輸入的處理精準度。位置編碼偏移機制
能根據輸入的參考圖像大小,動態調整位置編碼,顯著減少圖像在複製和貼上時與參考圖混淆的問題。視覺語言聯合訓練
為解決用家指令不規則、邏輯複雜的挑戰,團隊以視覺語言模型(VLM)與生成模型進行聯合訓練,使VLM能更好地理解複雜指令並轉化為結構化格式,大幅提升模型在真實場景的應用表現。
開放公眾使用 應用前景無限
DreamOmni2已於著名國際開源社區Github開放予公眾使用,更獲得數字藝術創作者認可支持,讚賞模型在理解氛圍感和抽象風格方面表現卓越,大幅降低了創作複雜圖像的門檻。
賈佳亞教授表示:「DreamOmni2標誌着多模態生成技術邁入全新階段,其不僅在性能上超越現有模型,更在技術架構上為AI圖像生成和編輯模型的未來發展奠定堅實基礎,為生成式人工智能產業注入新動能,同時為數字藝術設計、個人化媒體制作等領域帶來革命性改變,助力香港產學研和科研生態的蓬勃發展。」
註冊收取我們的最新消息
最新消息

太陽能電池的效能與壽命往往取決於材料之間的微小界面。香港科技大學(科大)研究人員近日參與兩項研究,發現透過精準設計的分子界面層,可顯著提升新一代鈣鈦礦疊層太陽能電池的效能及耐用性。
兩項研究分別刊登於學術期刊《Joule》(影響因子為37.1)及《自然—通訊》,雖然針對不同疊層架構,卻帶出同一個核心訊息:分子界面並非單純連接不同材料的被動層,而是可主動引導鈣鈦礦薄膜結晶、減少能量損失、促進電荷傳輸,並保護器件免受退化影響的重要設計平台。
這兩項研究由科大電子及計算機工程學系助理教授林彥宏教授及科大顯示與光電子全國重點實驗室高級經理楊思恩博士共同帶領,充分結合科大在鈣鈦礦界面設計、光學表徵及疊層器件物理方面的科研優勢。其中,科大電子及計算機工程學系研究助理教授李鳳珠博士領導《Joule》論文的研究工作;科大電子及計算機工程學系博士研究生張青清女士則為《自然—通訊》論文的主要研究團隊成員之一。

由香港大灣區圍棋促進會及香港科技大學(科大)聯合主辦的第四屆「四洲盃」香港國際大學生圍棋公開賽,於7月14日至18日在科大校園隆重舉行。賽事開幕典禮於今日(7月15日)在科大逸夫演藝中心盛大舉行,並非常榮幸邀請到香港特別行政區政府教育局局長蔡若蓮博士等重量級嘉賓蒞臨主禮。出席開幕儀式的嘉賓亦包括:香港大灣區圍棋促進會會長徐瑩女士、科大副校長(大學拓展)吳宏偉教授、四洲集團創辦人兼主席戴德豐博士、深圳市文化廣電旅遊體育局副局長何建輝先生、中央政府駐港聯絡辦宣傳文體部副部長林枬先生、外交部駐港特派員公署發言人兼新聞及公共關係部主任黃景睿先生、新華社亞太總分社社長孫承斌先生、中央廣播電視總台香港記者站站長王喜凱先生、中央廣播電視總台亞太總站副站長李風先生、先施集團主席、全國政協委員林曉暉先生、香港新聞工作者聯會會長張國良先生及科大跨學科學院院長屈華民教授等。

香港科技大學(科大)與印尼高等教育、科學及科技部簽署合作備忘錄,加強落實印尼政府資助獎學金框架,以培育卓越人才。是次合作進一步深化雙方夥伴關係,透過印尼最新推出的「嘉魯達獎學金」(the Garuda Scholarship),支持更多優秀印尼學生赴科大修讀本科課程。此合作備忘錄基於雙方於2024年5月簽訂的合作協議,旨在鞏固既有的獎學金機制,同時為雙方未來在學生實習、學術交流及科研合作等領域探討更多協同發展機會鋪路,攜手推動高等教育與創新科技發展。
協議早前由印尼高等教育、科學與科技部署任秘書長Badri Munir SUKOCO 教授及科大協理副校長(學術策略及數據分析)萊韻詩博士正式簽署。隨着協議落實,科大亦將於今年九月展開的新學年迎來第五批由印尼政府資助的優秀本科生。