








科大團隊研發AI模型 能協助減少全球農田氨氣排放達38%
有助達成聯合國可持續發展目標




在當今科技飛速發展的時代,人工智能(AI)已經成為推動創新和變革的核心動力。其中,AI模型扮演著至關重要的角色,為各個領域帶來前所未有的機會和挑戰。本文將深入探討AI模型的本質、分類、工作原理及其廣泛應用,並展望未來發展趨勢與隱憂。
1. 什麼是AI模型 (AI Models)?
AI模型(Artificial Intelligence Models)是一種基於數學和統計學原理,旨在模仿人類智能某些方面的電腦程序。開發人員輸入規則稱為算法 (algorithms), 使程序能夠做出決策、注意到模式並做出預測。 成功的模型具有用戶友好的介面。這意味著新用戶可以在沒有太多指示的情況下與之互動。 例如Bing Chat 是一款由AI驅動的聊天機器人應用程序 (AI-powered chatbot app), 可以與用戶進行來回對話。
2. AI模型有哪些分類?
AI模型可以根據學習方式和目標任務進行分類,主要包括:
- 監督式學習模型 (Supervised learning models): 利用標註數據進行訓練,用於分類、回歸等任務。
- 非監督式學習模型 (Unsupervised learning models): 從未標註數據中發現隱藏模式,常用於聚類和降維。
- 強化學習模型 (Reinforcement learning models):通過與環境交互獲得獎勵,用於決策和控制問題。
- 生成式模型 (Generative models): 基於給定輸入生成新的輸出,如文本生成和圖像合成。
以下是一些AI模型例子:
- GPT-3: 以大量文本數據上接受訓練的大型語言模型,能夠生成類似人類的文本。
- DALL-E: 根據文本描述創建圖像的AI系統。
- AlphaFold: 基於蛋白質的遺傳序列預測其3D結構的AI模型。
- AlphaGo: 一個下圍棋並擊敗人類專家的AI系統。
3. AI模型是如何工作的?
AI模型使用算法(algorithms)來識別數據中的模式和趨勢。多個算法共同組成一個AI程序或模型(model)。
AI模型的核心技術與訓練方法有哪些?
- 卷積神經網路 (Convolutional Neural Networks)
- 遞迴神經網路 (Recurrent neural networks)
- Transformer
這些神經網路透過層層傳遞和轉換資訊,學習數據的內在規律和模式。訓練高品質AI模型的關鍵在於自監督學習和遷移學習技術。自監督學習利用大規模、多樣化的未標註數據進行預訓練,使模型獲得通用的表示能力。而遷移學習則允許將預訓練模型應用於新的下游任務,大大提高了開發效率。除此之外,對抗訓練、元學習、聯邦學習等新興技術也為AI模型的訓練帶來了創新:
- 對抗訓練 (Adversarial Training) 透過生成對抗網路提高模型的泛化能力
- 元學習 (Meta-Learning) 使模型能夠快速適應新任務
- 聯邦學習 (Federated Learning) 在保護數據隱私的前提下,聚合多個數據源進行聯合訓練
生成式AI (Generative AI) 和大規模模型是當前AI模型發展的兩大重點。生成式AI旨有意義的輸出,如文本生成和圖像合成。而大規模模型則有更強的表達能力,能夠捕捉更複雜的模式,代表作品包括:
- GPT
- BERT
這些模型規模的不斷擴大是提升AI性能的有力驅動力。這些創新技術的融合應用,賦予了AI模型強大的學習和推理能力,推動著人工智能在多個領域的廣泛應用。
4. AI模型應用領域?
AI模型在多個領域展現出廣泛的應用前景:
- 自然語言處理 (ChatGPT):語言理解、文本生成、問答系統、機器翻譯等。
- 電腦視覺 (Vision Transformer):圖像識別、物體偵測、圖像分割、圖像生成等。
- 音訊/語音處理:語音識別、虛擬助理、多語種支援、音樂生成等。
- 其他領域:金融風險管理、醫療診斷輔助、客戶服務智能化等。
5. AI模型用什麼指標作評估其成效?
評估AI模型的性能是提高模型品質的關鍵環節。常用的評估指標包括準確率、精確率、召回率、F1分數等,需要根據具體任務選擇合適的指標體系。而在評估的基礎上,可以採取多種優化策略來提升模型性能,如數據增強、超參數調整、模型集成等。
6. AI模型的隱藏風險與挑戰
- 算法偏見:訓練數據的偏差可能導致AI模型做出不公平的決策。
- 隱私和安全:AI模型可能洩露敏感數據或被用於不當目的。
- 可解釋性:AI模型的決策過程常常是一個黑箱,缺乏透明度。
- 技術失控:人工智能的發展可能超出人類的控制範圍。
因此,我們需要建立完善的AI治理框架,透過技術手段和監管政策來應對這些挑戰。
7. AI模型的未來發展趨勢
- 計算能力提升:量子計算、腦機介面等新興技術將極大提高AI模型的計算能力。
- 算法創新:新的深度學習架構、聯邦學習等算法將不斷湧現。
- 數據爆炸:5G、物聯網等技術將產生大量新數據,為AI模型提供更豐富的訓練資源。
- 多模態融合:整合視覺、語音、文本等多種模態,實現更強大的AI系統。
- 人機協作:AI將成為人類的智能助手,在各個領域發揮輔助作用。
AI模型將深刻影響我們的生活、工作和思維方式,為我們將來開啟一個全新的智能時代。
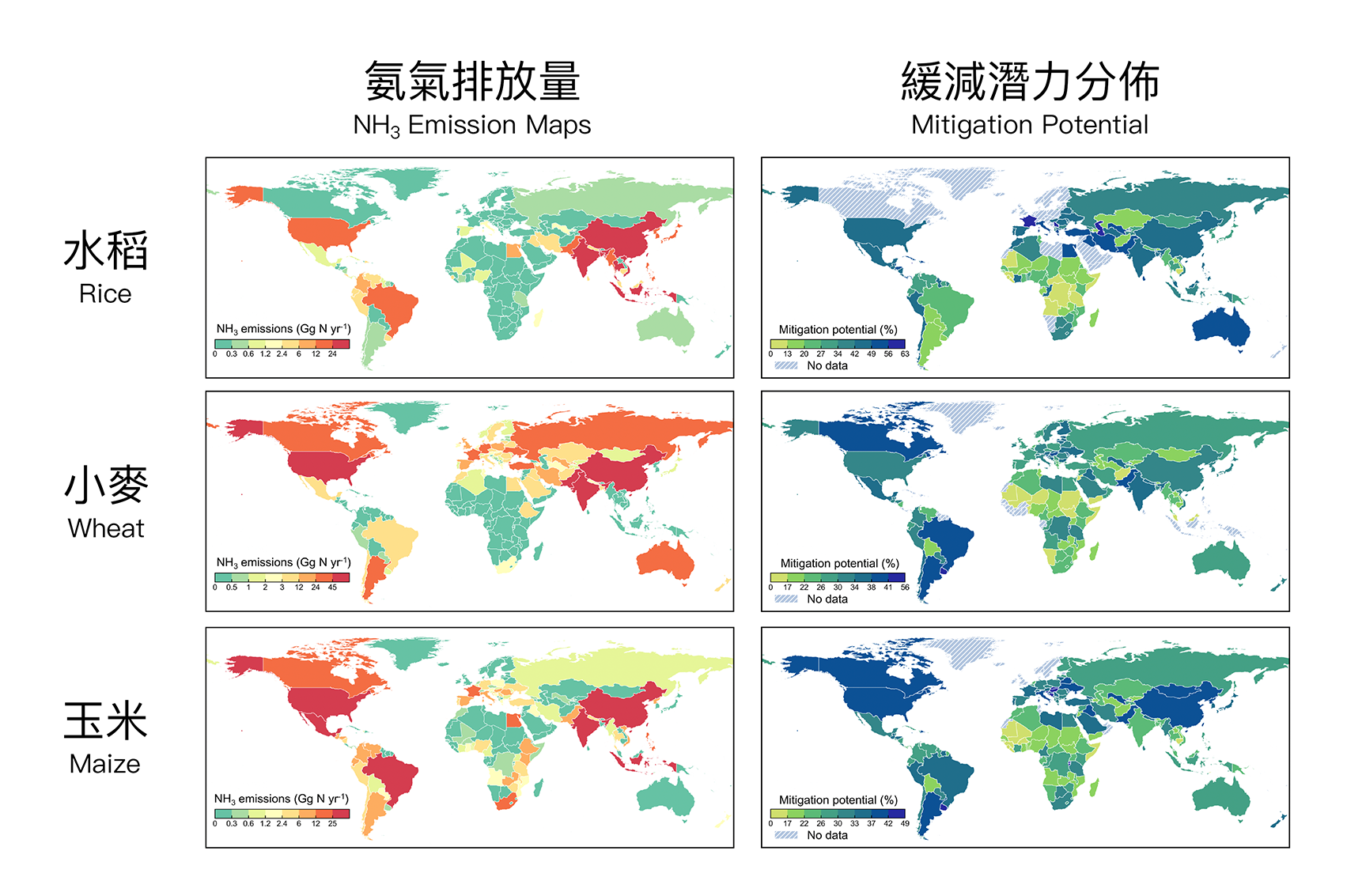
由香港科技大學(科大)領導的一支國際研究團隊,以人工智能技術(AI)研發出一個機器學習模型,能有效促進全球農田的氨減排。該研究發現,目前農田所排放的氨氣量(ammonia)(NH3)不但較預期為低,更發現採用優化的施肥管理能降低農田氨排放總量達38%,有助全球各地制定合適的減氨策略,並為落實聯合國「永續發展目標」當中有關確保糧食安全、消除飢餓,以及促進永續農業的目標帶來新希望。
多種農業及工業過程所釋放的氨,會污染空氣和水質,影響生態環境及人類健康。雖然氨並非溫室氣體,但進入土壤或大氣後,會形成一氧化二氮等化合物,成為強效溫室氣體,引致氣候變化。
三大主要農作物包括水稻、小麥和玉米皆釋放的氨氣,已佔全球農田氨排放總量的一半。隨著人口及糧食需求的持續增長,實現農田氨減排成為了全球可持續發展亟待解決的難題之一。然而,現時全球欠缺準確的數據統計,各國很難實施適合本國具體情況的有效減排策略。
有見及此,科大理學院數學系兼跨學科學院環境及可持續發展學部講座教授馮志雄教授,聯同南方科技大學(南科大)鄭一教授,領導研究團隊收集並分析全球不同地區於1985年至2022年間的田間觀測數據,並製成數據庫。
團隊利用AI及相關數據,研發出一個能預測農田氨排放率的機器學習模型,並分析氣候、土壤特質、農作物種類,以及灌溉、施肥及耕作等人為管理因素對氨排放的影響。該模型更能按不同地區的情況,建議最合適的施肥管理方針。例如,研究發現,由於溫度最影響亞洲地區小麥種植產生的氨排放量,面對全球暖化帶來的影響,76%位於亞洲的小麥田,可透過施用高效肥(enhanced-efficiency fertilizers )去降低氨排放量。
AI模型發現,倘世界各國以AI優化施肥管理的方針去減低氨排放,例如調整施肥時間、使用特定的肥料以及實施適當的種植和耕作方法等,可將該三種主要農作物的氨排放量減低約38%。當中,亞洲地區有最高的緩減潛力,其次則為北美及歐洲。由於研究預測,全球農田氨排放總量於2030-2060年的30年間將增長約4%至5.5%,意味即使只發揮少部分優化施肥管理的緩減潛力,仍能有效抵銷氨排放的增長。
馮教授表示:「世界各國於處理全球減氨排放議題上仍然面臨不少挑戰,例如成本高昂及農地規模偏小等。是次研究清晰勾劃了全球氨氣排放的現況,讓各國可制定相應對策,從而防治霧霾,並保障糧食安全。同時,此研究亦展示了大數據與AI科技對實現可持續發展目標的巨大潛能。」
研究成果已於科學權威《自然》學術期刊上發表。除科大與南科大外,團隊成員還包括天津大學、科羅拉多州立大學、北京大學、北京大學深圳研究生院、美國橡樹嶺國家實驗室、北京林業大學及康奈爾大學。文章的共同第一作者為科大博士生李庚及南科大研究助理教授徐鵬博士。
關於香港科技大學
香港科技大學(科大)(https://www.hkust.edu.hk/) 是國際知名的研究型大學,其科學、工程、商業管理及人文社會科學領域,均臻達世界一流水準。科大校園國際化,提供全人教育及跨學科研究,培育具國際視野、創業精神及創新思維的優秀人才。逾八成的科大研究,於香港的大學教育資助委員會「2020研究評審工作」被評為「國際卓越」或「世界領先」水平。我們於最新的《泰晤士高等教育全球年輕大學排名榜2023》中排行第二,而科大的畢業生在2023年度的全球大學就業能力排名第29位,位於亞洲院校前列。截至2023年9月,科大成員共創立了1,747間至今活躍的初創公司,當中包括9間獨角獸企業和13間成功退場的公司(上市集資或被併購),合共創造了逾4,000億港元的經濟效益。投資推廣署早前引用「2021年QS世界大學學科排名」,展示躋身全球百大的五所本地大學在多個創新領域的表現,當中科大在四個工程與材料科學領域的排名為本地大學之首。
傳媒查詢:
林淑媛
電話﹕2358 6313
電郵﹕anitalam@ust.hk
鄧慧儀
電話﹕2358 6306
電郵﹕gloriatang@ust.hk
註冊收取我們的最新消息
最新消息

太陽能電池的效能與壽命往往取決於材料之間的微小界面。香港科技大學(科大)研究人員近日參與兩項研究,發現透過精準設計的分子界面層,可顯著提升新一代鈣鈦礦疊層太陽能電池的效能及耐用性。
兩項研究分別刊登於學術期刊《Joule》(影響因子為37.1)及《自然—通訊》,雖然針對不同疊層架構,卻帶出同一個核心訊息:分子界面並非單純連接不同材料的被動層,而是可主動引導鈣鈦礦薄膜結晶、減少能量損失、促進電荷傳輸,並保護器件免受退化影響的重要設計平台。
這兩項研究由科大電子及計算機工程學系助理教授林彥宏教授及科大顯示與光電子全國重點實驗室高級經理楊思恩博士共同帶領,充分結合科大在鈣鈦礦界面設計、光學表徵及疊層器件物理方面的科研優勢。其中,科大電子及計算機工程學系研究助理教授李鳳珠博士領導《Joule》論文的研究工作;科大電子及計算機工程學系博士研究生張青清女士則為《自然—通訊》論文的主要研究團隊成員之一。

由香港大灣區圍棋促進會及香港科技大學(科大)聯合主辦的第四屆「四洲盃」香港國際大學生圍棋公開賽,於7月14日至18日在科大校園隆重舉行。賽事開幕典禮於今日(7月15日)在科大逸夫演藝中心盛大舉行,並非常榮幸邀請到香港特別行政區政府教育局局長蔡若蓮博士等重量級嘉賓蒞臨主禮。出席開幕儀式的嘉賓亦包括:香港大灣區圍棋促進會會長徐瑩女士、科大副校長(大學拓展)吳宏偉教授、四洲集團創辦人兼主席戴德豐博士、深圳市文化廣電旅遊體育局副局長何建輝先生、中央政府駐港聯絡辦宣傳文體部副部長林枬先生、外交部駐港特派員公署發言人兼新聞及公共關係部主任黃景睿先生、新華社亞太總分社社長孫承斌先生、中央廣播電視總台香港記者站站長王喜凱先生、中央廣播電視總台亞太總站副站長李風先生、先施集團主席、全國政協委員林曉暉先生、香港新聞工作者聯會會長張國良先生及科大跨學科學院院長屈華民教授等。

香港科技大學(科大)一直緊貼時代步伐,因應市場人才需求改革課程。繼去年新推出的生物醫學及健康科學課程成為今年競爭最激烈的課程之一,科大將於新學年推出必修人工智能(AI)通識課程,提升學生在人機協作、AI應用的能力和專業知識。另外,科大的獎學金及學生支援措施與本港主要大學水平相若,並致力透過獎學金、海外學習資助及豐富的發展機會,為學生提供全面而多元的學習體驗。
AI通識課程打造創新人才
為裝備學生迎接人工智能(AI)時代帶來的機遇與挑戰,科大早於2021/22學年率先推出延伸主修(Major + X)課程,讓學生在主修學科以外,選修人工智能、可持續發展等前沿領域,至今已有逾1,450名學生修讀AI相關課程。